1. 인덱스(INDEX) 의미
2. 인덱스(INDEX)를 생성해야 할 때
3. 인덱스(INDEX) 생성, 삭제 방법
4. 인덱스 조회
5. 인덱스 리빌드(REBUILD)
1. 인덱스(INDEX) 의미
인덱스(INDEX)란 테이블의 데이터를 빨리 찾기 위해 생성하는 데이터베이스 객체이다. 인덱스가 존재하면 SQL 명령문의 처리 속도가 향상되며(인덱스 유무와 조회 결과는 동일) 일반적으로 칼럼 단위로 생성한다. 인덱스의 가장 일반적인 내부 구조는 'B-TREE' 구조로, 가장 상위의 Root Node, 가장 하위의 Leaf Node, 그리고 이들을 연결하는 Branch Node로 이루어져 있다. 상위 노드는 하위 노드 값의 범위를 가지고 있으며 Leaf Node에 데이터 로우(ROW)가 존재한다. 또한 인덱스와 테이블 내 실제 데이터는 다른 공간에 위치하여 관리된다.

2. 인덱스(INDEX)를 생성해야 할 때
앞서 인덱스를 처리 속도 향상을 위해 생성한다고 언급했지만 인덱스가 있다고 항상 빠르기만 한 것은 아니다. 상황에 따라서는 인덱스가 있는 것이 오히려 속도를 늦추거나 성능을 저하시키도 한다. 따라서 인덱스를 생성해야 할 때만 만드는 것이 효율적이다.
<생성하는 것이 효율적인 경우>
- WHERE 절에서 자주 사용되는 칼럼일 경우
- 데이터 중복이 적은 경우(데이터 중복 높은 칼럼 인덱스는 비효율적)
- 조인에 많이 사용되는 칼럼일 경우
- 조회(select) 위주의 테이블일 경우(잦은 insert / update / delete 시 매우 비효율적)
3. 인덱스(INDEX) 생성, 삭제 방법
(1) 인덱스 생성
|
1
2
3
4
5
|
CREATE (UNIQUE) INDEX 인덱스명
ON 테이블명(칼럼1 (asc or desc)); ---- 단일 인덱스(하나의 칼럼)일 경우
CREATE (UNIQUE) INDEX 인덱스명
ON 테이블명(칼럼1 (asc or desc), 칼럼2 (asc or desc)); ---- 결합 인덱스(두 개 이상의 칼럼)일 경우
|
- 고유인덱스를 생성할 경우 UNIQUE를 포함하고 인덱스키를 오름차순 정렬 시에는 ASC, 내림차순 정렬 시에는 DESC를 적어준다.
EX) student 테이블에서 이름 칼럼 고유인덱스 idx_stud_name 생성
|
1
2
|
CREATE UNIQUE INDEX idx_stud_name
ON student(name);
|
- 고유인덱스는 유일한 값을 가지는 칼럼에 생성(중복 값 X)
- 해당 칼럼에 중복되는 값 있으면 고유인덱스 생성되지 않는다
EX) professor 테이블에서 고용일 칼럼 비고유인덱스 idx_prof_hiredate 생성(내림차순으로 생성)
|
1
2
|
CREATE UNIQUE INDEX idx_prof_hiredate
ON professor(hiredate DESC);
|
- 비고유인덱스 값이 중복되는 칼럼에 생성
EX) emp 테이블에서 empno, ename 칼럼을 결합인덱스로 생성
|
1
2
|
CREATE UNIQUE INDEX idx_emp_empno_name
ON emp(empno, ename);
|
EX) professor 테이블에서 profno, hiredate 칼럼을 결합인덱스로 생성(profno 오름차순, hiredate 내림차순으로 생성)
|
1
2
|
CREATE UNIQUE INDEX idx_prof_pno_hdate
ON professor(profno ASC, hiredate DESC);
|
또한 테이블 생성 시 PRIMARY KEY(기본키), UNIQUE(유니크)를 지정하면 해당 칼럼은 자동으로 인덱스 생성된다. 이러한 인덱스는 CREATE 명령문으로 만든 인덱스와는 다르게 해당 제약조건을 삭제해야 인덱스도 삭제된다.
(2) 인덱스 삭제
|
1
|
DROP INDEX 인덱스명;
|
EX) student 테이블에 생성된 인덱스 idx_stud_name 삭제
|
1
|
DROP INDEX idx_stud_name;
|
EX) professor 테이블에 생성된 인덱스 idx_prof_hiredate 삭제
|
1
|
DROP INDEX idx_prof_hiredate;
|
4. 인덱스 조회
(1) USER_INDEXES
: 현재 계정이 소유하고 있는 인덱스 정보 조회(인덱스명, 유일성 등)
EX) professor 테이블에 생성했던 인덱스 IDX_PROF_HIREDATE 조회(USER_INDEXES로 조회)
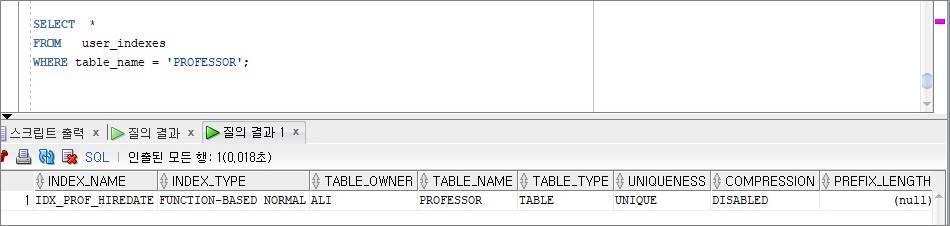
- 원하는 정보만 선별해서 조회할 수도 있다

(2) USER_IND_COLUMNS
: 현재 계정이 소유하고 있는 인덱스 칼럼 정보 조회(인덱스명, 테이블명, 칼럼명, 정렬 등)

- USER_IND_COLUMNS 역시 원하는 정보만 선별해서 조회 가능

5. 인덱스 리빌드(REBUILD)
인덱스가 생성되어 있는 테이블에서 잦은 데이터 추가, 수정이 일어나는 경우 인덱스의 구조(대부분 B-TREE구조)의 불균형을 초래한다. 이러한 경우 인덱스 리빌드(인덱스 재구성)를 통해 인덱스 내부 노드를 정리해줄 필요가 있다.
|
1
|
ALTER INDEX 인덱스명 REBUILD;
|
EX) professor 테이블에 생성된 인덱스 IDX_PROF_HIREDATE 재구성
|
1
|
ALTER INDEX 인덱스명 IDX_PROF_HIREDATE REBUILD;
|
'Database > Oracle' 카테고리의 다른 글
| [오라클(Oracle) ] 뷰(VIEW) (0) | 2022.04.20 |
|---|---|
| [오라클(Oracle) ] 임시 테이블 (0) | 2022.04.19 |
| [오라클(Oracle) ] 서브쿼리(SUBQUERY) / 다중행 서브쿼리 / 다중칼럼 서브쿼리 / 상호연관 서브쿼리 (0) | 2022.04.19 |
| [오라클(Oracle) ] 셀프 조인(SELF JOIN) (0) | 2022.04.17 |
| [오라클(Oracle) ] 외부 조인 / OUTER JOIN / ANSI JOIN (0) | 2022.04.17 |




댓글